




About Me
I am a final-year Ph.D. Candidate in Computer Science at
During my Ph.D. study, I have had the opportunity to spend two memorable internships at
Recent Updates
- Oct 2025 My paper on Multi-modal Few-shot Learning is presented at ICCV 2025.
- Jun 2025 Started Research Internship at Amazon AGI team.
- Apr 2025 My intern paper at Microsoft is accepted to CVPR 2025.
- Jun 2024 Started Research Internship at Microsoft Responsible and Open AI Research Team.
- Apr 2024 3 papers accepted to CVPR 2024. My intern paper at Amazon is designated as "Highlight" paper.
- Sep 2022 Started as an Applied Scientist Intern at Amazon's AWS AI Lab.
- Apr 2022 One paper accepted to CVPR 2022.
Selected Publications

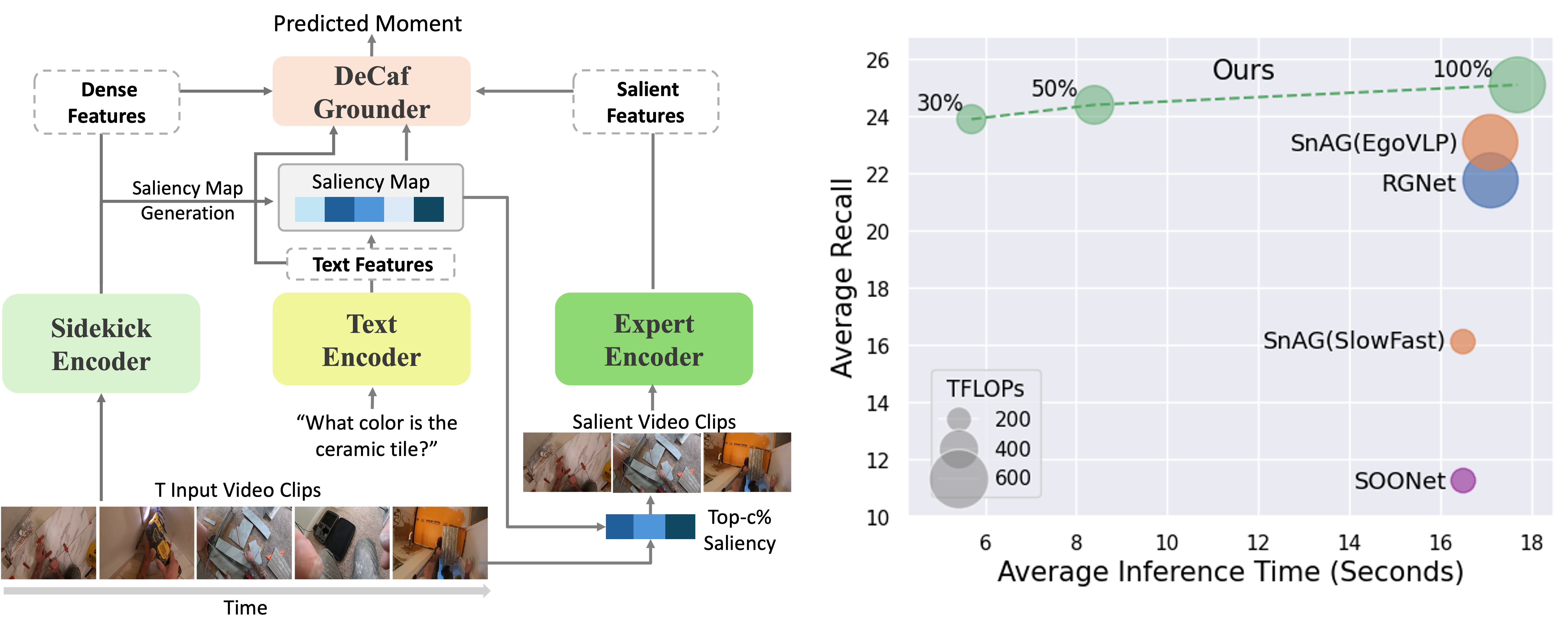
DeCafNet: Delegate and Conquer for Efficient Temporal Grounding in Long Videos
- A Delegate-and-Conquer framework for efficient coarse-to-fine Long Video Temporal Grounding.
- Efficient Video Encoder for end-to-end training on Ego4D with one A100.
- SOTA accuracy with 47%-66% lower computation.
- APPLICATION: improve VLLMs to efficiently handle hour-long videos.
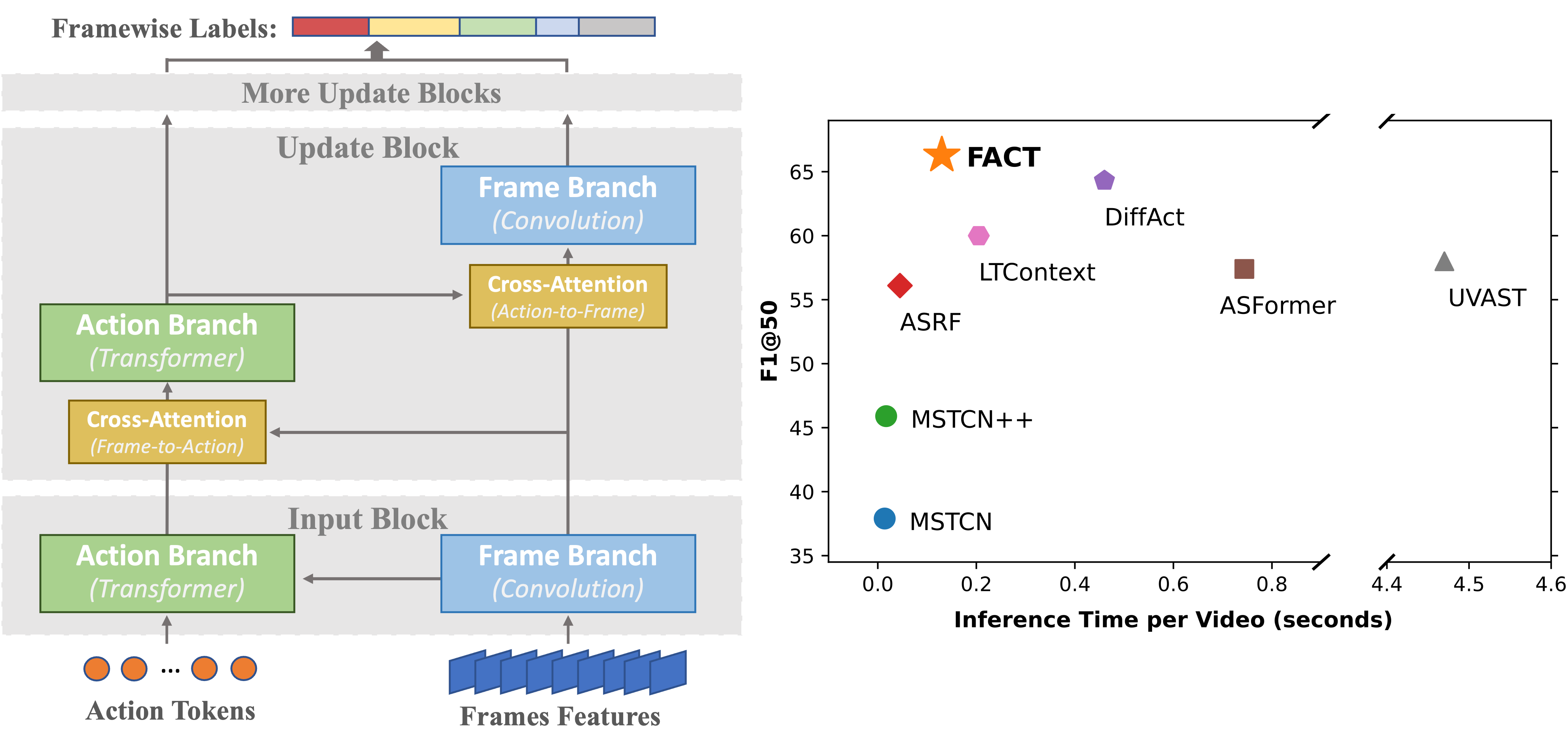
FACT: Frame-Action Cross-Attention Temporal Modeling for Efficient Fully-Supervised Action Segmentation
- New Long Temporal Reasoning paradigm with parallel modeling of frame details and temporal events/actions.
- Action Tokens Design for dynamic video condensing and enabling text-data input.
- SOTA accuracy with 3x inference speed.
- APPLICATION: better Assistant AI; allow Multi-Modality Learning.
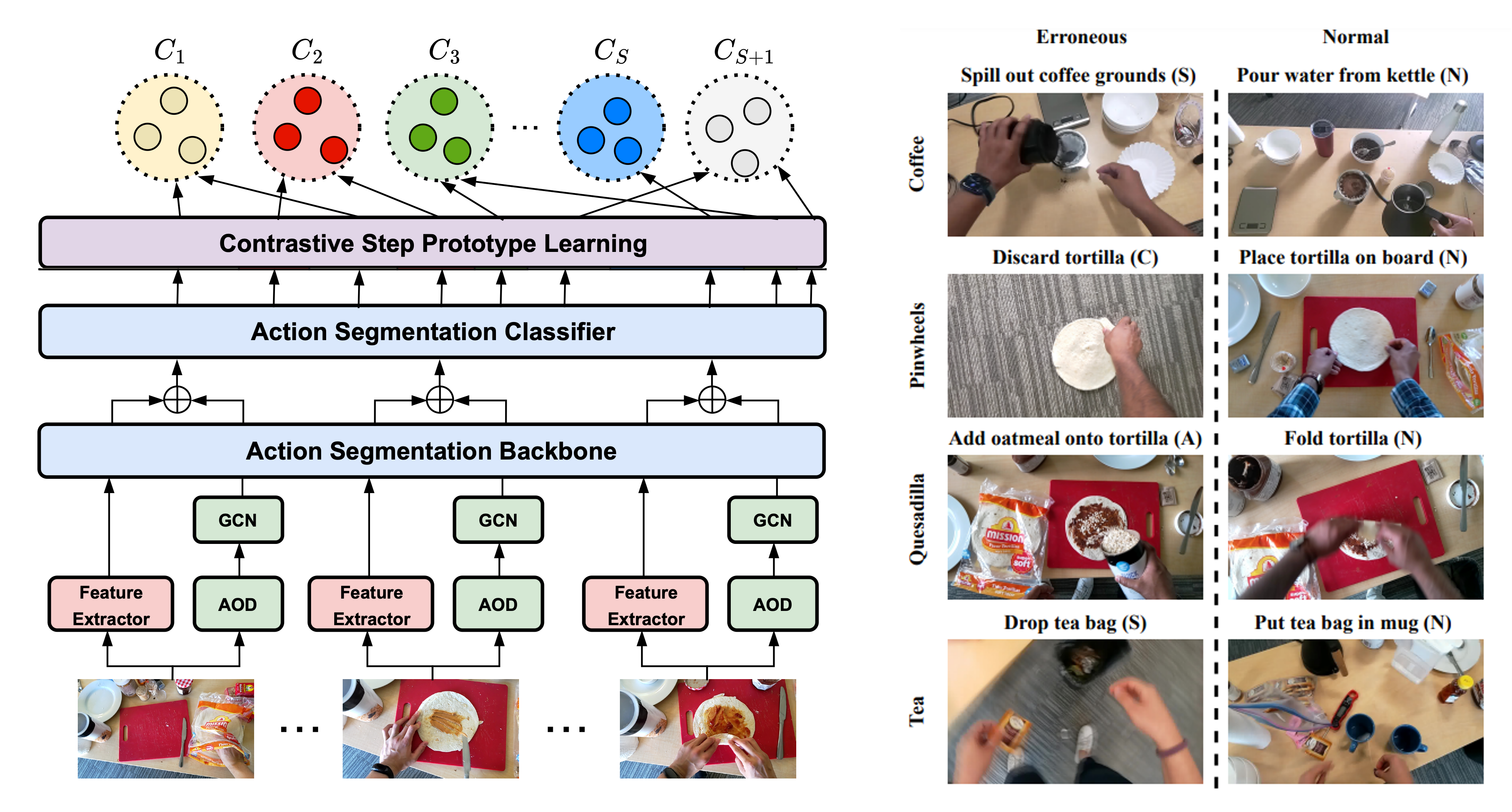
- A One-class Error Detection method in procedural videos.
- First Egocentric Procedural Error Detection (EgoPER) dataset with extensive error types.
- APPLICATION: error detection for Egocentric Understanding and Assistant AI.
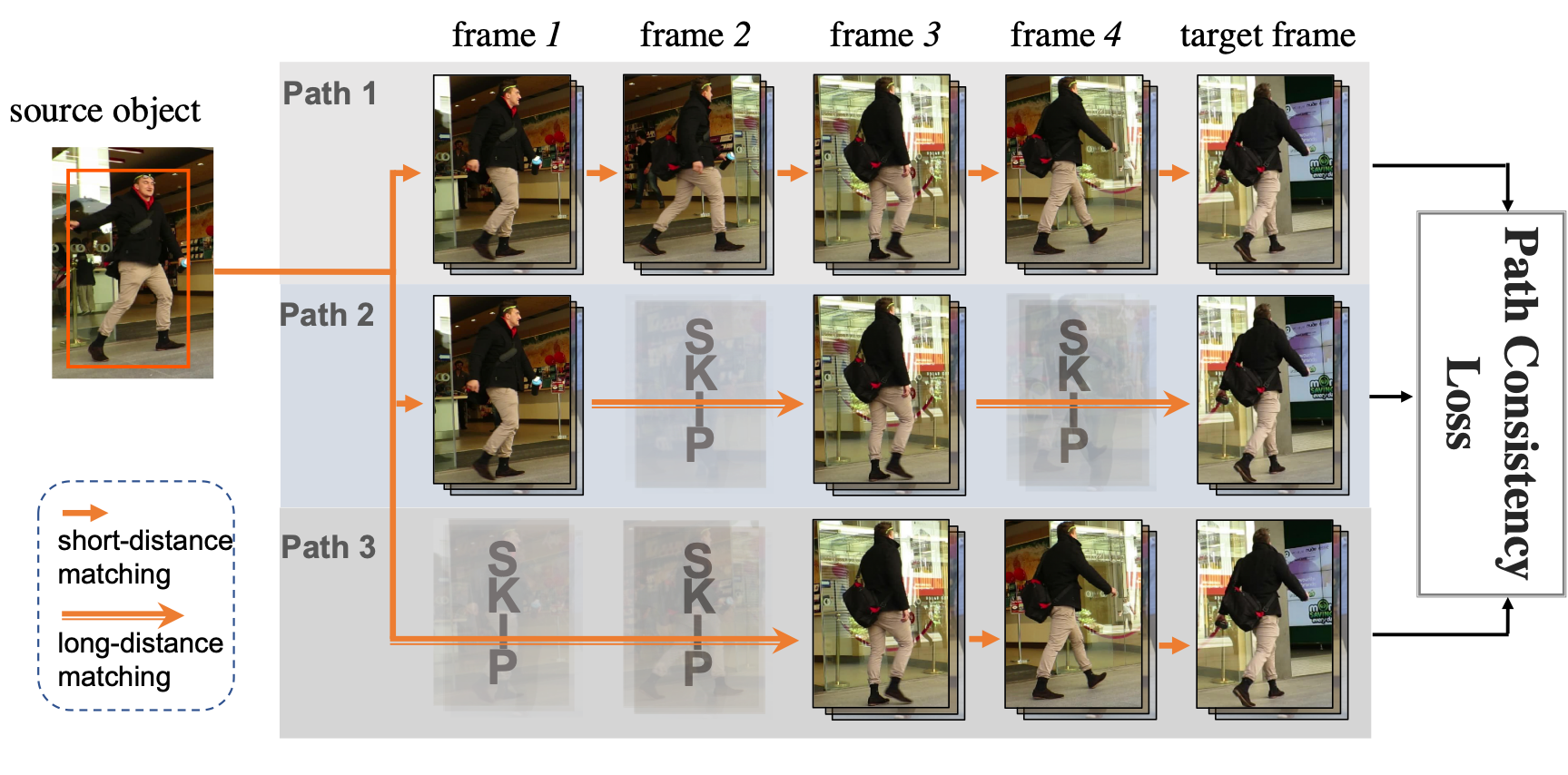
- Self-Supervised Consistency Loss for robust Multi-Object Tracking without manual labels.
- Superior or comparable to supervised methods on popular benchmarks.
- APPLICATION: Robust object tracking for Egocentric Understanding and Scene Understanding.
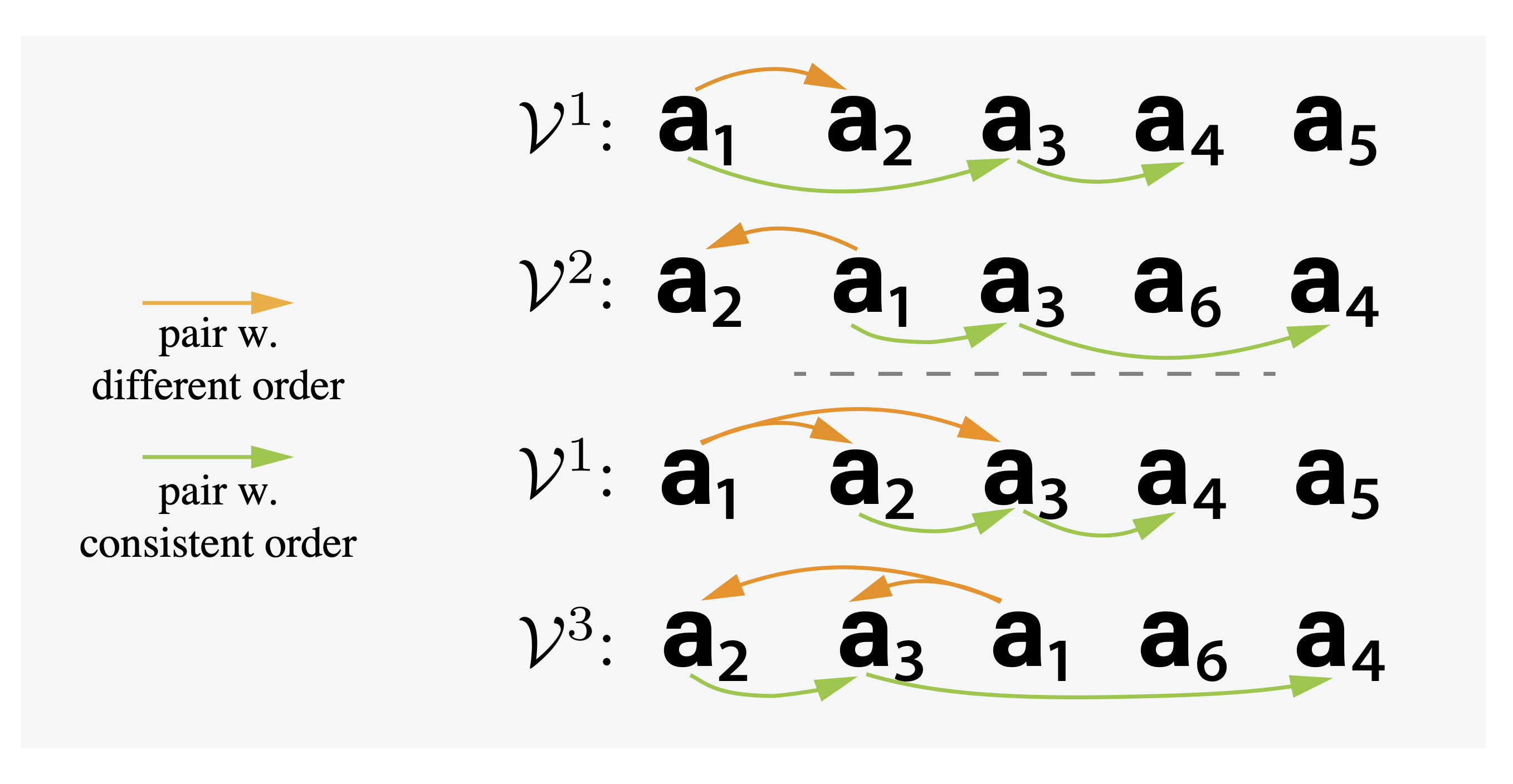
Set-Supervised Action Learning in Procedural Task Videos via Pairwise Order Consistency
- Video-Text Alignment between video frames and unordered sets of actions in video parsed from video narrations.
- New differentiable Sequence Metric for weakly-supervised video-text alignment.
- APPLICATION: learn video-text semantic space for VLLMor Video Generation.

Weakly-supervised Action Segmentation and Alignment via Transcript-Aware Union-of-subspaces Learning
- New Union-of-Subspace network for accurate Action Modeling and capturing complex action variations.
- Contrastive Learning for weakly-supervised video-text alignment.
- APPLICATION: Video-Text Alignment.
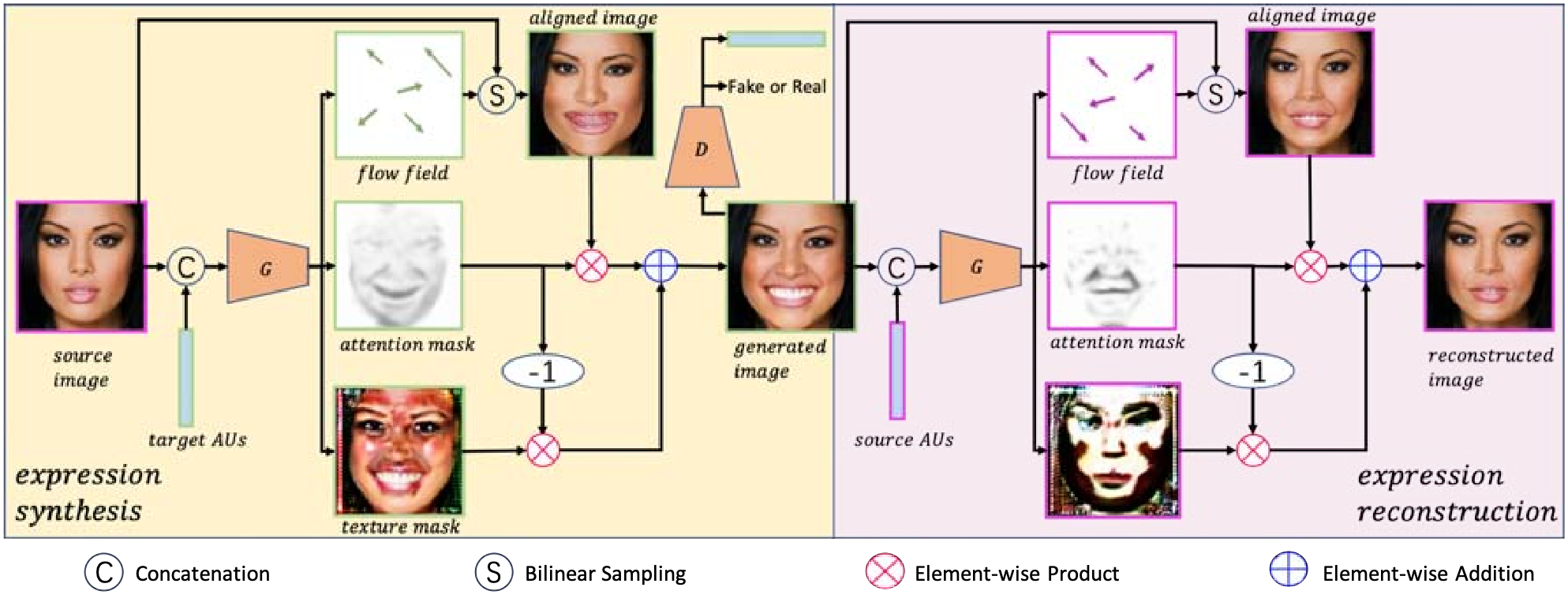
Dft-Net: Disentanglement of Face Deformation and Texture Synthesis for Expression Editing
ICIP 2019
Paper- Two-Branch GAN network for facial expression edition.
- Warping branch for expression transform and Generative branch for refinement.
- APPLICATION: Controlled Image Generation and Expression Editing.
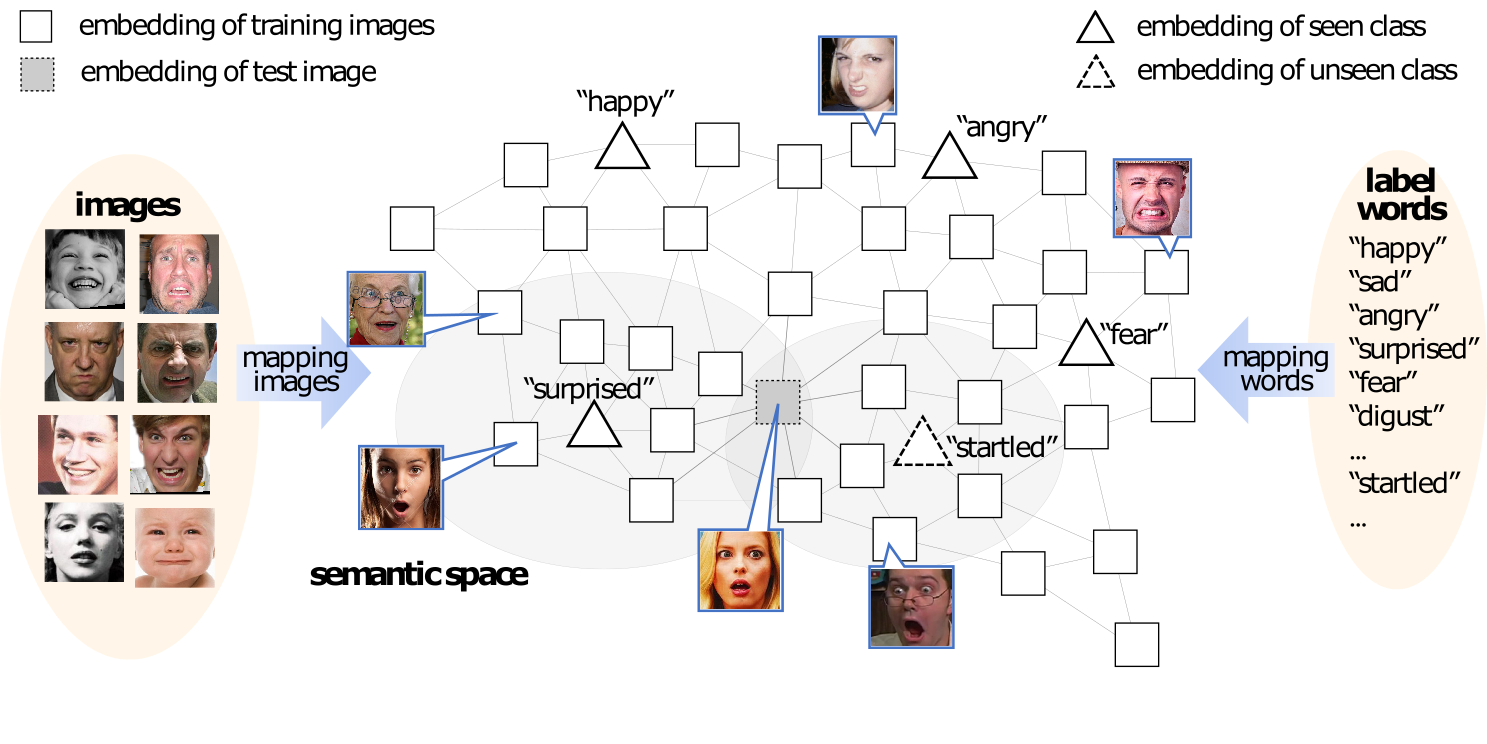
Zero-Shot Facial Expression Recognition with Multi-Label Label Propagation
- Transductive Label Propagation method for Zero-Shot facial expression recognition.
- The first Open-Set Facial Expression Recognition dataset.
- APPLICATION: Open-World affection computing for human-computer interaction.
Experience
Worked on end-to-end MLLM for spatial-temporal multi-object grounding in video.

Worked on efficient end-to-end models for text-based video temporal grounding.
Worked on Self-Supervised and Robust Multi-Object Tracking.

Focusing on Video-Text Understanding, Action Segmentation, Egocentric Understanding and Video Data Generation.

Worked on Zero-Shot Facial Recognition and Expression Editing.

Developed CUDNN function for Volta GPU and GPU performance simulator.

Graduated with a Major GPA of 3.98/4. Conducted research in Image Segmentation with Prof. Zhen Zhang and Document QA with Prof. Kyunghyun Cho.